
How much bandwidth do I need? Always a hard question. It gets harder as you use more network links, and have to start considering what happens when one or more links fail, leaving you with reduced bandwidth.
The simple way to determine how much total bandwidth you need is to make a guess, and then adjust until the peaks in your bandwidth graphs stay below the 100% line. The more complex answer is that it depends on the bandwidth elasticity of the applications that generate your network traffic.
Applications are bandwidth elastic (sometimes known as "TCP friendly") when they adapt how much data they send to available bandwidth. They're inelastic when they keep sending the same amount of data even though the network can't handle that amount of data. Let's look at a few examples in more detail.
I'm assuming the bandwidth need throughout the day shown in this graph:
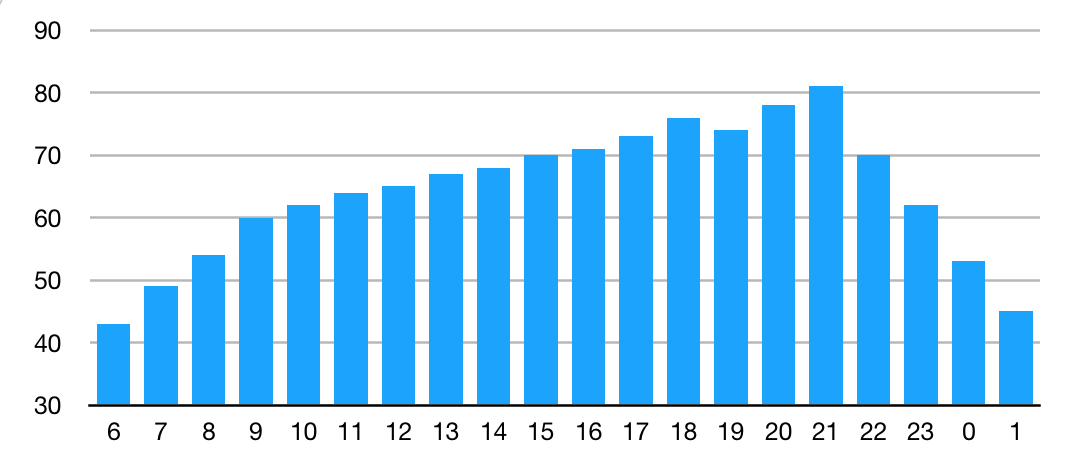
Between 21:00 and 22:00, normal bandwidth use reaches a peak of just over 80% of available capacity. But now we lose 25% of our bandwidth, so we have a higher bandwidth need than we can accommodate between 18:00 - 19:00 and 20:00 - 22:00, shown in red below:
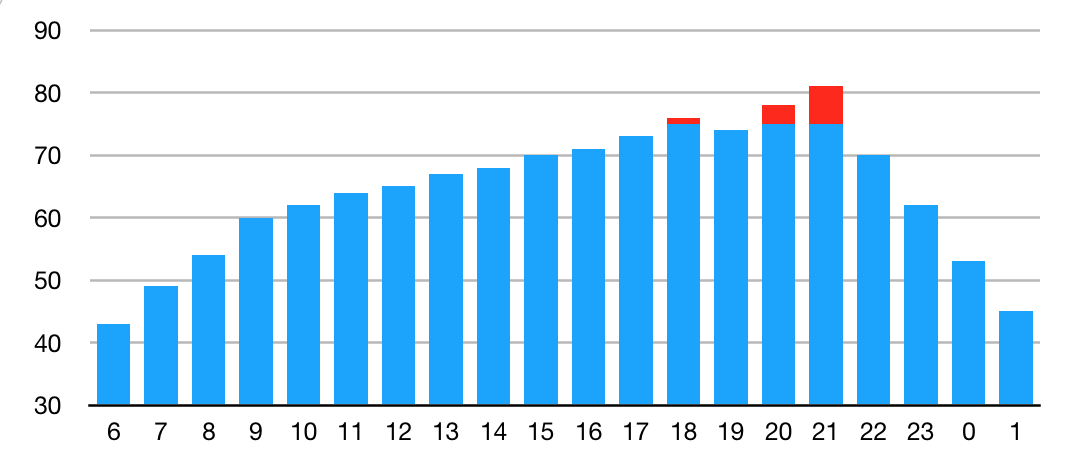
Let's look at the behavior of applications with different bandwidth elasticity.
Read the article - posted 2019-03-18
Geoff Huston has written a post on the APNIC blog congratulating BGP with its 30th birthday. BGP version 1 was published as RFC 1105 in June of 1989. Five years later, the BGP version 4 was published as RFC 1654. And we're still using BGP-4 today, 25 years later! Lots of things, including IPv6 support, were added later in backward compatible ways.
As usual, Geoff's story is comprehensive with lots of interesting details. For instance:
From time to time we see proposals to use geo-based addressing schemes and gain aggregation efficiencies through routing these geo-summaries rather than fine-grained prefixes.
Sorry about that. 😀 I still think it could work, though.
Well worth a read.
Read the article - posted 2019-06-10
Last week, there was a large route leak that involved Swiss hosting company Safe Host and China Telecom. The route leak made internet traffic for European telecoms operators KPN, Swisscom and Bouygues Telecom, among others, flow through Safe Host and China Telecom against the wishes of the telecom operators involved. See this Ars Technica story for more details.
In this post, I'm going to explain how the interaction between the technical and business aspects of internet routing have made this issue so difficult to fix. At the end I'll briefly describe a proposal that I think can actually make that happen.
Read the article - posted 2019-06-13
Last week, I suggested it's time fix those BGP route leaks. I live by the words everybody complains about the weather, but nobody does anything about it, so as such I wrote an Internet-Draft with the protocol changes necessary:
draft-van-beijnum-sidrops-pathrpki-00
I think we can stop these route leaks with a relatively modest change to RPKI: by combining the ASes the origin trusts and the ASes the operator of an RPKI relying party server trusts, we have a list of all the ASes that may legitimately appear in the AS path as seen from this particular vantage point.
Read the article - posted 2019-06-20
As I was writing my RPKI path validation draft last week, I considered the issue of filtering BGP AS paths with AS_SETs in them.
Turns out that I'm not the only one who feels AS_SETs are unnecessary: there's an RFC saying the exact same thing: RFC 6472.
Read the article - posted 2019-06-24
Afgelopen maandagmiddag was er een grote storing in het telefonienetwerk van KPN, waarbij ondermeer het alarmnummer 112 zo'n drie uur niet bereikbaar was. Hoe kan het dat een telefoontje op een vaste lijn van KPN naar een meldkamer in de veiligheidsregio Groningen last heeft van dezelfde storing als een telefoontje van een Vodafone-gebruiker naar een meldkamer in de veiligheidsregio Limburg-Zuid? Dinsdag kwam het antwoord: een softwarefout. Het mocht niet baten dat het betreffende systeem viervoudig uitgevoerd was.
In de telefonie is al vele jaren geleden het zogenaamde intelligent network ingevoerd. Voor die tijd waren vaste nummers gekoppeld aan wijkcentrales en mobiele nummers aan de mobiele operator. Als je dus van de ene kant van de stad naar de andere verhuisde, of van de ene mobiele operator naar de andere, dan kreeg je een nieuw nummer. Met IN was dat niet meer nodig: de telefooncentrale vraag aan een centrale database waar telefoontjes naartoe gerouteerd moeten worden. Probleem is wel dat het telefoonnetwerk nu afhankelijk is van een klein aantal centrale systemen. (En Voice over IP (VoIP) heeft dat versterkt.) Voorheen kon je nog binnen je eigen stadsdeel bellen zolang de wijkcentrale het deed, ook al lag de rest van het telefoonnetwerk plat.
We zien nu dezelfde ontwikkeling op ons af komen in de internetwereld. (...)
Read the article - posted 2019-06-25
Seven years ago, the RIPE NCC, which serves Europe, the middle east and the former Soviet Union, was no longer able to give out IPv4 address space to ISPs and other networks as needed. From that point on, the "last /8" policy came into effect, which meant that each "RIPE member" or local internet registry (LIR) could get one last IPv4 /22 (block of 1024 addresses). It very much looks like that last bit of IPv4 address space will run out before the end of the year.
Right before the final /8 policy came into effect, the RIPE NCC was giving out about a million IPv4 addresses per week. In 2019, they gave out a million IPv4 addresses every three months in the form of those final /22s. And now it's a million IPv4 addresses every six weeks, with two million left to go. Apparently, many new LIRs are set up to get one of those /22s while they last.
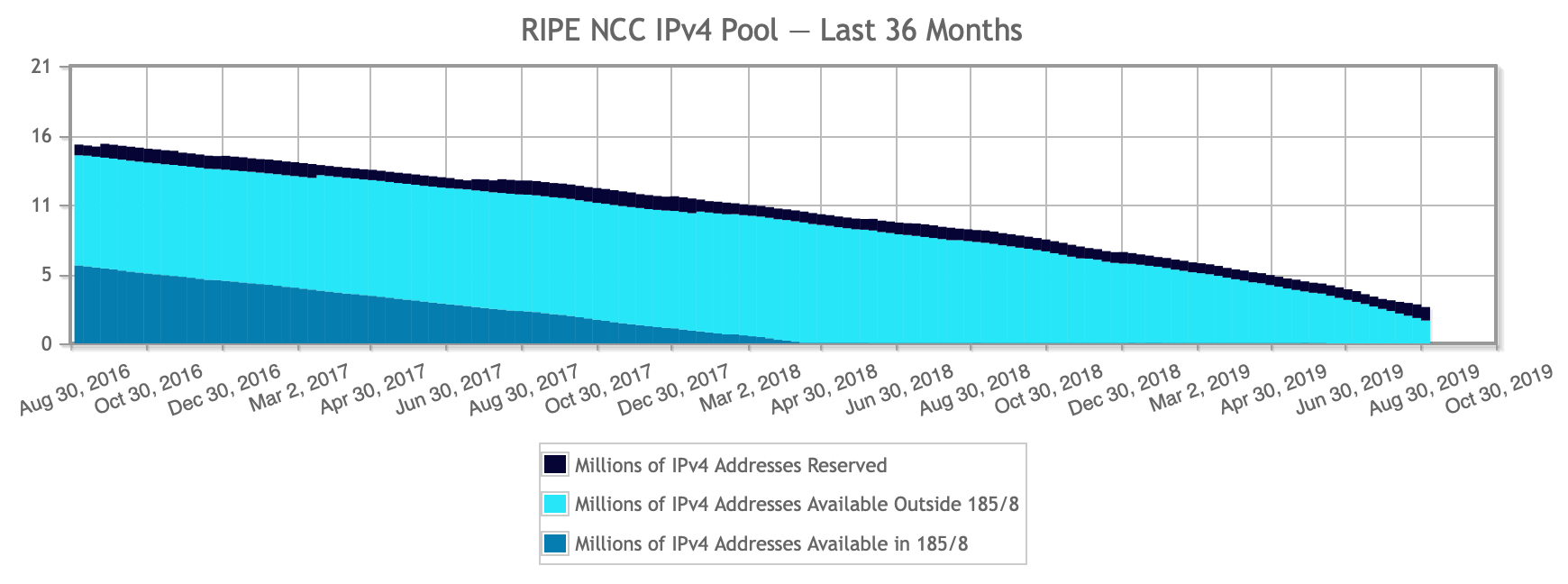 latest version of this image on the RIPE website
latest version of this image on the RIPE website
So in all likelihood RIPE will move from the final /8 policy to a new policy, where LIRs are put on a waiting list and get a /24 as those become available, before the end of 2019.
Permalink - posted 2019-09-09
In this month's edition of The ISP Column Why is Securing BGP just so Damn Hard? Geoff Huston asks himself exactly this question. He lists ten reasons. I don't agree with most of them: this is a solvable problem.
Read the article - posted 2019-09-20
During his talk about 30 years of BGP, Geoff Huston said something along the lines of "someone should come up with another type of routing protocol besides distance vector and link state". That is of course too delicious a challenge to ignore...
Read the article - posted 2019-10-15
Less than three months ago I wrote about how the uptake of the remaining IPv4 addresses at RIPE was accelerating, with the RIPE NCC likely to run out of the addresses set aside in the "last /8" before the end of the year. And so they did, two days ago. So as of this week, it's no longer possible to request address space in the RIPE service region (Europe, former Soviet Union, Middle East) and get them within a somewhat predictable period...
Read the article - posted 2019-11-27
There are some advantages to filtering out packets with invalid addresses in them. That would be a packet with a private source or destination address, for instance. Those never have any business traveling across the internet. (Not to be confused with BCP 38 filtering.) For instance, there have been instances where spammers grab an unused prefix, start announcing it in BGP, do a spam run and then drop the prefix. When packets with private addresses enter your network, bad things may happen if you use those addresses yourself. And these invalid "martian" packets are just an annoyance, using up traffic and generating log entries.
Read the article - posted 2019-11-28
Presentation slides from my lightning talk "AS paths: long, longer, longest" at the RIPE-79 meeting in Rotterdam, 18 October 2019.
Permalink - posted 2019-11-29
Twitter's Jack Dorsey, in (of course) a Twitter thread:
Twitter is funding a small independent team of up to five open source architects, engineers, and designers to develop an open and decentralized standard for social media. The goal is for Twitter to ultimately be a client of this standard.
This is interesting on several levels. I'll mostly talk about the protocol design part of this, but before I do that: when has a business that's pretty much in a monopolist position ever voluntarily given up that position? They must really be feeling the pushback against "content and conversation that sparks controversy and outrage", and see this as a way out.
Read the article - posted 2019-12-17
In a paper for the HotNets'19, seven researchers admit that "beating BGP is harder than we thought". (Discovered through Aaron '0x88cc' Glenn.) The researchers looked at techniques used by big content delivery networks, including Google, Microsoft and Facebook, to deliver content to users as quickly as possible. This varies from using DNS redirects to PoPs (points of presence) close to the user, using BGP anycast to route requests to a PoP closeby and keeping data within the CDN's network as long as possible ("late exit" or "colt potato" routing).
Turns out, all this extra effort only manages to beat BGP as deployed on the public internet a small fraction of the time.
Read the article - posted 2019-12-30